









11 KiB
3NAR (n nearest neighbor avrage rapid)
par Ludovic CASTIGLIA
Problématique
Le but de ce projet était de trouver un algorithme généraliste (qui puisse être utilisé dans différents cas d'utilisations), rapide (qui n'a pas une grande complexité ou qui trouve des solutions dans un temps raisonnable) et précis (qui trouve des solutions proches de la réalité dans une majorité des cas).
Pour ce faire, j'avais plusieurs outils à ma disposition, mais celui sur lequel je me suis penché est l'algorithme Knn (n plus proche voisin). C'est un algorithme assez simple qui n'a pas réellement besoin d'entraînement contrairement à un réseau de neurones, mais qui à cause de sa complexité algorithmique devient inutilisable dans sa forme naïve pour de larges volumes de données. J'ai donc dû trouver un moyen de modifier l'implémentation de Knn pour réduire sa complexité tout en gardant si possible l'aspect généraliste et précis de Knn.
Algorithme et avantage par rapport à Knn
Point commun entre Knn et 3nar :
Ces deux algorithmes sont capables d'inférer une ou plusieurs valeurs à partir d'une ou plusieurs valeurs en entrer grâce à des exemples fournit au préalable. Ils sont également capables de réaliser de la classification ou de la multi-classification (c'est-à-dire associer une ou plusieurs class à une ou un groupe de donnée en entrer).
Outre leurs capacités, ils fonctionnent de la même façon. La phase d'entraînement consiste simplement à enregistrer en mémoire les différentes données d'exemples ainsi que leurs valeurs associées (valeur, groupe de valeurs, class ou groupe de class). Ensuite pour inférer la/les valeur.s/class associé à de nouvels coordonnées, on trouve les n exemples les plus proches et on retourne la moyenne des valeurs des n point multiplié par un poid calculé en fonction de leur distance.
Problème de Knn :
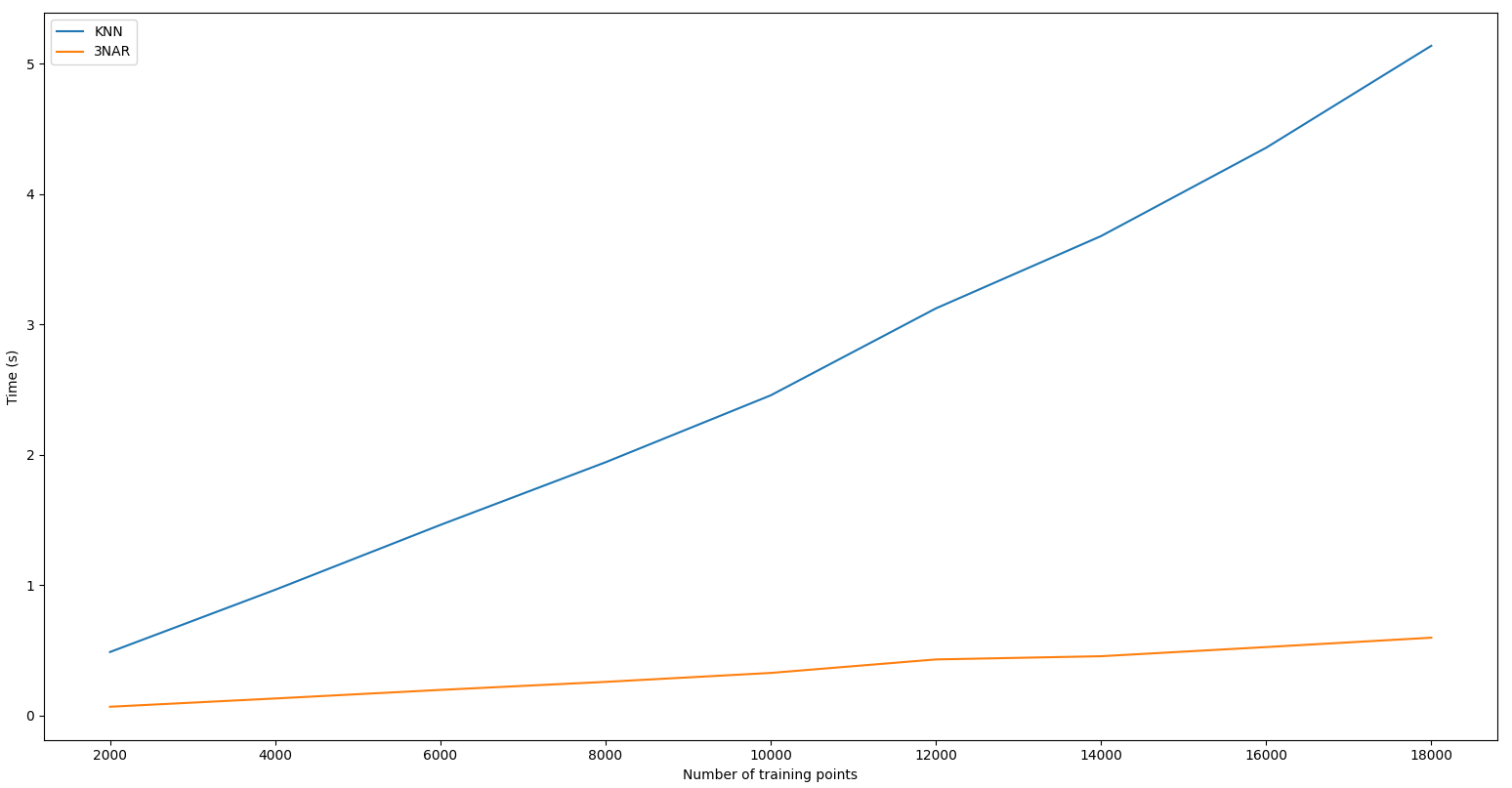
Le problème de l'implémentation naïve de Knn est que pour trouver les n points les plus proches d'un nouveau point A, on calcule la distance de chaque point en mémoire avec A puis on trouve les n points avec la plus petite distance. Ce qui veut dire que plus le nombre de points d'exemple en mémoire augmente plus on calcule de distance pour trouver la valeur d'un point. Ainsi, comme nous pouvons le voir sur le graphique ci-dessous la complexité de l'algorithme est linéaire

Solution de 3nar :
Pour trouver les n points les plus proches de A sans avoir à calculer les distances avec tous les autres points, 3nar profite de la phase d'ajout des points pour enregistrer des informations
À l'initialisation, nous allons créer un espace orthonormé avec m dimension (le nombre de coordonner des exemples). Et nous allons remplir cet espace avec un certain nombre de sous-espace à déterminer en fonction des cas d'utilisations (ces espaces sont tous de tailles égaux et sont eux aussi orthonormé). Ensuite, lors de la phase d'entraînement, il suffit d'ajouter les points dans les différents sous-espaces en fonction de leurs coordonnées. Pour trouver le sous-espace si vos sous-espaces sont dans une liste, vous pouvez calculer l'index avec cette formule:
Soit t, la taille d'un sous-espace et nb, le nombre de sous-espace dans une dimension:

Dans le cas de ce programme, les sous-espaces sont stockés dans un tenseur et les coordonnées du sous-espace d'un point sont données par la division euclidienne de toutes les coordonnées du point par t.
Une fois toutes les données ajoutées dans le modèle, il est temps de lui demander la valeur de nouveau point. Pour cela, l'algorithme va trouver dans quel sous-espace le point serait, s'il existait dans sa mémoire. Puis il vérifie s'il a assez de points dans ce sous-espace dans une distance (dont on parlera plus tard). Si c'est le cas alors il calcule les distances avec ces points et il retourne les n plus faibles. Sinon on trouve les sous-espaces à proximité et on recommence jusqu'à avoir assez de points. Cela permet de grandement réduire le nombre de calcul de distance entre points pour trouver les n points les plus proches.
Concernant la distance, elle est calculée en fonction des coordonnées du point que l'on veut deviner, de la taille du sous-espace et en fonction de son centre. Cette distance doit être la plus grande possible (pour capter le plus de point) tout en ne sortant en aucun point du sous-espace (pour être sûr de réellement trouver les points les plus proches). Cette distance peut être calculée de la façon suivante:
 dist = t/2 - max(ABx,ABy) + t * nbSousEspaceAutour
dist = t/2 - max(ABx,ABy) + t * nbSousEspaceAutour
À noter que c'est un exemple en 2d, le même calcule peut-être généralisé pour un nombre m de dimension.
Dans le cas de ce programme, je n'ai pas utilisé cette distance à la place, j'ai utilisé cette formule qui me garantis de ne jamais sortir de l'espace et qui est plus simple à calculer:

dist = t * nbSousEspaceAutour
Je vais maintenant vous expliquer l'algorithme qui me permet de trouver les sous-espaces autour d'un sous-espace. On appelle une fonction findCoordAround qui vas appeler getCoordDifférente pour tous les nombres entre 0 et la distance des sous-espaces autour. getCoordDifférente quant à elle, va appeler getCompletVariationOfCoord pour tout tableau de coordonner avec pour valeurs que des valeurs unique entre -la distance autour et +la distance autour. getCompletVariationOfCoord va appeler getPermutationOfCoord pour toutes les coordonnées qui possède les coordonners passé en paramètre puis comble les coordonners avec les valeurs ordonnées de ses coordonners. Enfin getPermutationOfCoord vas ajouter dans une liste de sous-espaces toutes les permutations des coordonners passé en entrée.
Enfin, dernière optimisation de l'algorithme, pour éviter de recalculer en boucle les différents sous-espaces autour d'un sous-espace (ce qui est coûteux à faire dynamiquement pour m dimension), on enregistre en mémoire le résultat de cette opération. Puis lorsque l'on veut recalculer ce résultat, on a juste à l'appliquer à notre cas (car le sous-espace ne sera pas le même, mais les sous-espaces autour seront aux mêmes distances et dans les mêmes directions).
Ainsi, toutes ses optimisations permettent de grandement réduire la complexité de 3nar par rapport à Knn cependant comme vous pouvez le voir sur les graphiques suivants, la complexité reste linéaire que l'on fasse varier le nombre de points inféré ou le nombre de données d'entraînement:

Cependant, il y a encore un dernier point intéressant à discuter avec 3nar c'est l'impact d'un paramètre sur la complexité de l'algorithme. Plus on divise l'espace en sous-espace plus la complexité de l'algorithme se réduit. Vous pouvez voir ce phénomène grâce au graphique suivant:

Cas d'utilisations
Comme nous l'avons vue dans la première partie, 3nar est utilisable dans plein de contexte. Ce ne sera pas souvent le meilleur algorithme, mais dans la plupart des cas, il rendra un résultat satisfaisant en un temps satisfaisant. Vous pouvez retrouver 4 cas d'utilisations aussi appelées demo dans ce projet que vous pouvez lancer au choix avec Knn ou 3nar. Pour lancer les demos placer vous dans le répertoire et appeler les script python de demo en ajoutant à votre commande le nom de l'algo (knn ou nnnar).
demo1.py
Dans la demo 1, nous utilisons le csv ./data/maison.csv. Nous calculons une valeur en sortie en fonction de 4 valeurs en entrer. Nous calculons le prix des maisons en fonction du nombre de m², du nombre de chambres, du nombre de salles de bain et de l'étage. Sur ces données et avec 80% du dataset en entraînement et 20% en test, on arrive au alentour de 90% de précisions.
demo2.py
Dans cet exemple, nous générons aléatoirement une fonction polynomiale du second degré avec des paramètres étant des réels compris entre -5 et 5. Puis après avoir fourni à 3nar quelques exemples (100 dans notre cas), nous utlisons l'algorithme pour prédire de nouvelles valeurs choisit aléatoirement.
demo3.py
Cette demo est plus visuel est présente un cas d'utilisation ou nous devons calculer plusieurs valeurs en fonction de plusieurs valeurs. Dans cette demo, nous prenons une image (./data/img.jpg) puis de manière aléatoire on vient remplacer des pixels par des pixels blancs. Puis nous venons retrouver algorithmiquement les pixels qui ont été changés (on pourrait aussi faire cette étape avec 3nar mais ça serait plus long), puis enfin, on vient calculer la valeur de ces pixels avec 3nar. Dans cette exemple, on commence à avoir pas mal de donnée et on voit l'avantage de 3nar par rapport à Knn.
demo4.py
Dans cet exemple, on fait la classification des espèces d'Iris à partir de la taille de la largeur de la tige et des pétales. En quelques secondes, on arrive à avoir au alentour de 95% de précision.
À noter que pour les démos, je n'ai pas de dataset d'évaluation seulement un dataset de test, car je n'ai pas d'entraînement à proprement parler à réaliser (comme de la backpropagation) donc le dataset de test renvoie forcément le même résultat que le dataset d'évaluation.